On Explaining and Interpreting Machine Learning: An Overview
Not a day goes by without seeing a clickbait article about Artificial Intelligence (AI) and Machine Learning (ML), almost always with a picture of a robot doing human (?) things:

Aside from all the buzz around AI and ML, these are really exciting times. We’ve seen tremendous advances in many domains like Computer Vision (CV) and Natural Language Processing (NLP) — there is a new paper showing up on arXiv every week that improves the state-of-the-art. This rapid progress has been possible thanks to both academia and industry. Big tech companies have many folks working on ML research, and complex ML models are being used for consumer use.
There are many factors that contributed to this progress, one is more available compute power. This means that we can train larger models in shorter time, and perform inference quicker. While this is fantastic, it is more challenging to understand these models. Let’s say we have a convolutional neural network (CNN) to classify images, that has 25 layers and 5 million parameters. Given an image of a cat, it classifies it as a pencil. Why did it do so? What part(s) of the image caused this? Did I over-fit my CNN? Did I make deep learning gods angry?
You might say “Who cares if I misclassified this cat image? I’ll just add 25 more layers and train another CNN!”. You can, but there are many ML models in use today that affect people’s lives every day and understanding them matters. These applications range from computing the likelihood of a defendant becoming a recidivist in the US courts1 to assessing a person’s creditworthiness when they apply for a loan. In order to establish transparency and trust between such complex models and users, and to avoid any hidden errors/biases while training these models, it is important that there are ways to help them explain and interpret.
This mini-post series is intended to give an overview on explaining and understanding such models. At this point, let’s make it clear that we are talking about supervised machine learning models where given an input, we attempt to predict an output (cat image → cat, Frodo Baggins applying for a loan at Bank of Shire to travel around Middle Earth → 800 credit score).2
We will ask two basic questions to better understand the topic in this blog series:
- What?: we will define the problem of interpreting ML models and different levels of interpretability.
- (This blog post)3
- Why?: we will talk about why this matters. (Will be the next)
What?
As discussed in the beginning, machine learning models are getting more and more complex, thanks to more compute power and our ability to be able to train them. Just to put things into perspective, here are two examples:
- In “ancient times”, it was not uncommon to use linear models, using a method such as linear regression, that had fewer than 100 parameters. A trivial example for this is as follows: Let’s say we have a simple linear model that uses three variables to predict the market value of a house:

Interpreting this model is trivial: Each additional room will add 50 points to the market value while each additional bathroom will add 20 points and so on.
- In “modern times”, models are much, much more complex. Just take a look at this figure on how number of parameters of ImageNet models have changed over the years, from this awesome paper called “Green AI”4:
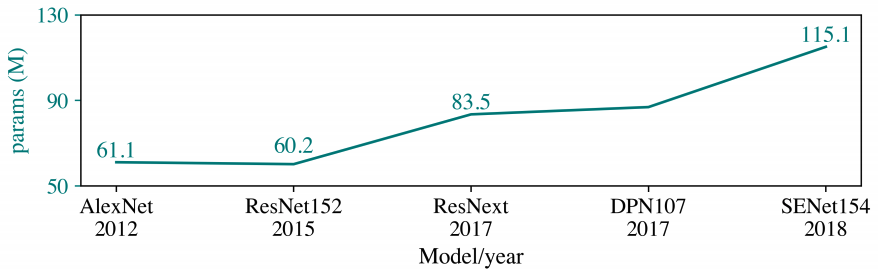
Now the state-of-the-art has 115 million parameters and 154 layers!
In general, the interpretability in supervised ML framework is regarded as a trade-off against accuracy: A simple model such as linear regression is easy to understand but is not likely to perform as well as a deep neural network (DNN), while it is not straightforward to understand DNNs. There’s a lot of research going on about explaining these complex models better.
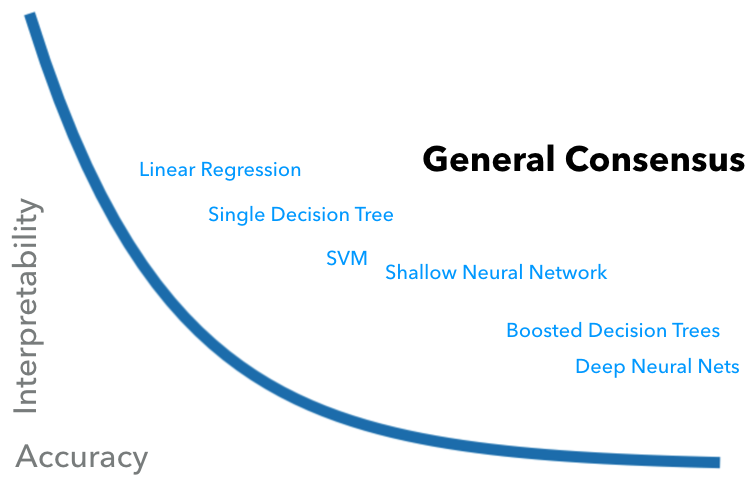
However, I think that this view oversimplifies and does not really explain (no pun intended) the entire picture of an ML prediction/classification pipeline in terms of interpretability. Interpreting a ML pipeline not only depends on model type/complexity but also the features used as inputs to the model.
Let’s illustrate this with a simple example. Let’s say we have a dataset of images of faces and non-faces and we want to classify whether an input image is of a face or not:

There are many ways to tackle this problem, but we will take a look at three ways (two extreme and one moderate solution) to illustrate how much interpretability can change based on features and ML model used:
Case 1, Learn nothing
- Features: Hand-engineered
- Model: Hand-engineered In this case, we don’t perform any machine learning per se. As an expert, we were able to hand-engineer features called “eye-detector” and “nose-detector”⁵. They output positive responses when there is an eye or a nose in the photo. Whenever there is a positive response for both detectors, we predict that it is a face image:
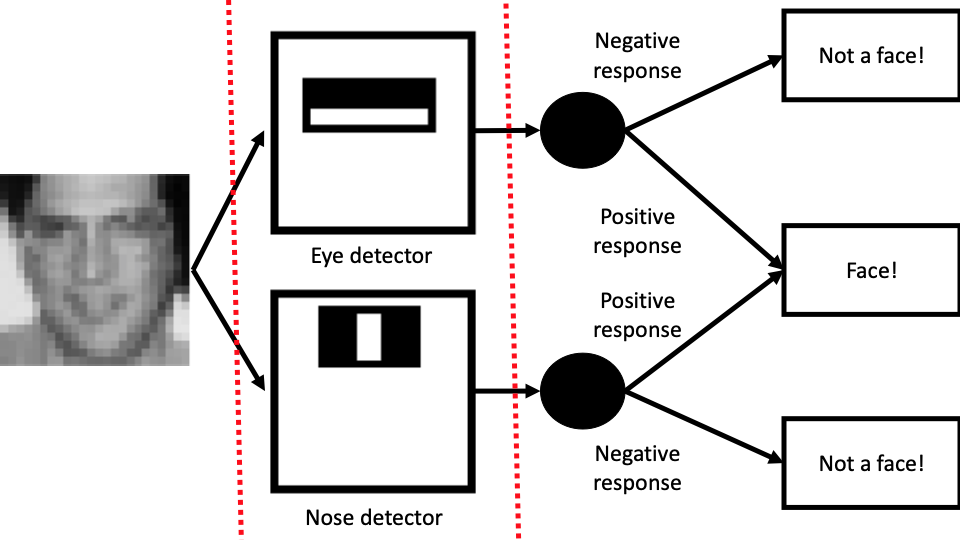
Dashed red lines above split this workflow into 3 parts: Input, feature generation, and classification. As one would expect, it is quite trivial to interpret the outcome of this model.
Case 2, Learn the model, not the features
- Features: Hand-engineered
- Model: Learned
In this case, we still think that our hand-engineered features are useful, and we keep them. However, we use them to feed into a model so that we can learn something that potentially performs better:
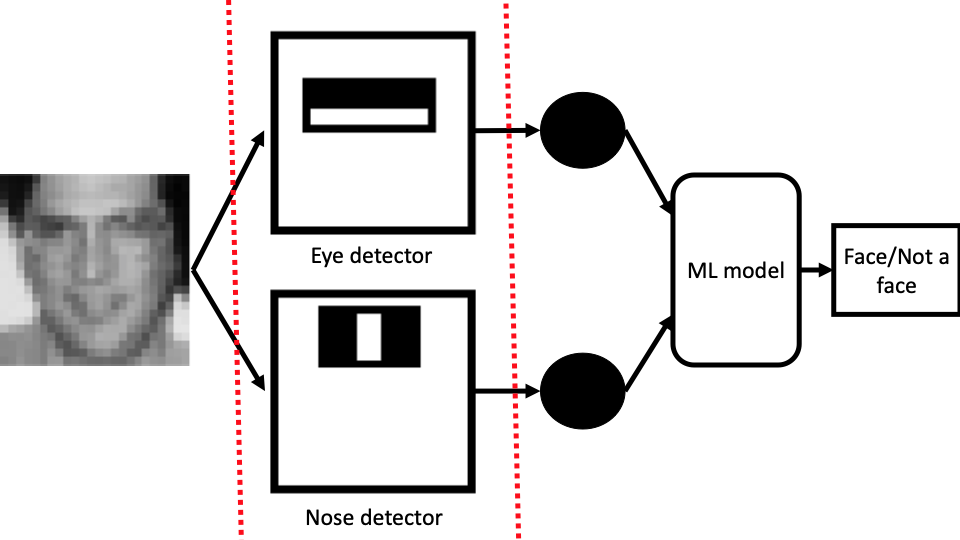
Depending on the type of the ML model we use, it might be either trivial (a linear model) or less trivial (an ensemble or a DNN) to explain the outcome of this workflow.
Case 3, Learn everything
- Features and Model: Learned jointly
This is the case that made neural nets quite popular, we only feed raw pixels values as inputs to an ML model and learn the classification problem in an end-to-end fashion. This is the workflow that has been winning the ImageNet object detection competition since 2012:
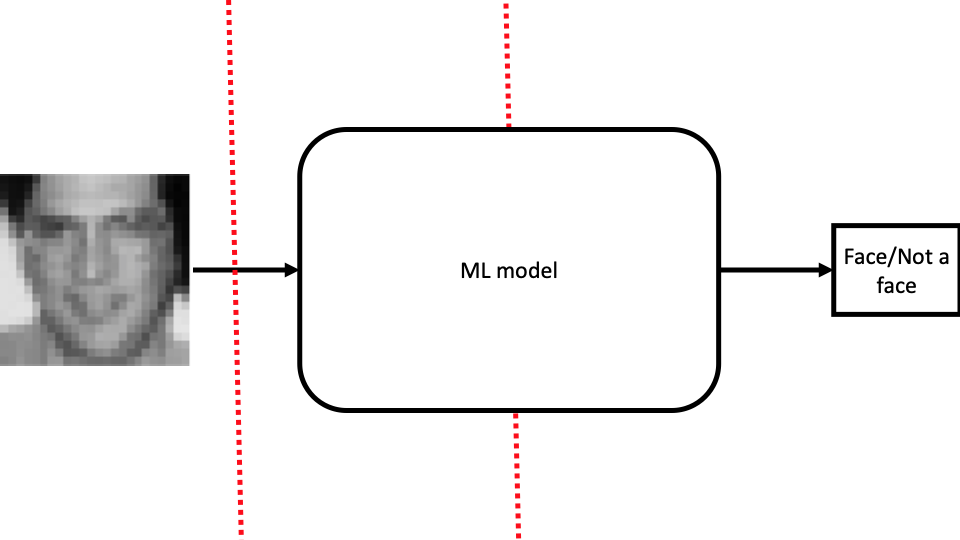
A trivial ML model used in this setting is unlikely to perform as well as a complex model like CNN. Given a large dataset, one would expect a CNN perform the best compared to all the cases we covered. However, explaining this one is the most challenging: Why did it classify an image as face (Was it the hair, eyes, eyebrows, lips? Did it learn different features specific to faces? Or was there something inherent about the non-face images, and it learned non-face features?) is the hardest to explain.
As you can see, interpretability in ML is a spectrum — it depends on what types of features along with what type of ML model one uses:

It is unlikely that there will ever be a universal solution for all cases, but there is a lot of exciting research going on — especially about explaining the outcome of an ML model!
In the next blog post, we will attempt to answer the question “Why”: Reasons why we need to explain/interpret models.
References
-
https://en.wikipedia.org/wiki/COMPAS_(software) ↩
-
All the papers I’ve come across in interpreting ML models are focused on supervised models. I think it would be fascinating and quite useful if there were research for unsupervised models. (for example: explaining generative models, learned embeddings) ↩
-
I’ll be using the terms explainability and interpretability interchangeably in this post. Both terms are being used loosely in many papers while there is not a global definition in this context. I would highly recommend reading “The Mythos of Model Interpretability” by Zachary Lipton. (https://arxiv.org/abs/1606.03490) ↩
-
Schwartz, Roy, et al. “Green AI.” arXiv preprint arXiv:1907.10597 (2019). (https://arxiv.org/pdf/1907.10597.pdf) ↩