On Explaining and Interpreting Machine Learning: Why
In the first part of our blog series on explainability/interpretability in machine learning (ML) and artificial intelligence (AI), we covered the “What” part. We argued that explainability depends not only on the complexity of the ML model used, but the workflow as a whole. In this part, we will attempt to answer the “Why” question: Why does explainability matter?
Two reasons why explainability matters
There are two parts in ML why explainability is important, each has a subject of interest and a goal to accomplish:
-
Model Trainer and Quality Assurance: This side of the story happens before an ML model is deployed and used — this is the part where an ML model is being trained/built. Many folks with many titles (Statistician, Research Scientist, ML Engineer, Data Scientist, and many more) are the main stakeholders in this part. At a very high level, there is a set of data points (e.g. cat and dog images), targets (e.g. image #1 is a cat, image #2 is a dog) and an objective to achieve (e.g. maximize overall accuracy to classify cat & dog images). Folks do their due diligence to ensure that the final model is as accurate as possible and performs “as-intended” in the wild. Unfortunately, other than “building a model that performs the best in our hold-out set”, many things can go wrong without knowing. Just to name a few: Possible bugs in the feature generation phase (if applicable), unknown corner cases where the model fails, development and “real” dataset mismatch, and many more. A must-read book, The Ethical Algorithm: The Science of Socially Aware Algorithm Design1, has an astonishing example for the data mismatch:
> In the early days of the perceptron the army decided to train an artificial neural network to recognize tanks partly > hidden behind trees in the woods. They took a number of pictures of a woods without tanks, and then pictures of > the same woods with tanks clearly sticking out from behind trees. Then they trained a net to discriminate > the two classes of pictures. The results were impressive, and the army was even more impressed when it > turned out that the net could generalize its knowledge to pictures from each set that had not been used > in training the net. > Just to make sure that the net had indeed learned to recognize partially hidden tanks, however, the > researchers took some more pictures in the same woods and showed them to the trained net. They were > shocked and depressed to find that the new pictures the net totally failed to discriminate between > pictures of trees with partially concealed tanks behind them and just plain trees. The mystery was > finally solved when someone noticed that the training pictures of the woods without tanks were > taken on a cloudy day, whereas those with tanks were taken on a sunny day. The net had learned > to recognize and generalize the difference between a woods with and without shadows! Therefore, it is very crucial to think hard about these issues, and build standard tools before a model is deployed. Explainability is one tool to help practitioners diagnose such issues and fix them. -
User and Trust: This is the part of the story when the model is deployed and is being used in the wild. Depending on the application, users either passively consume the ML outcome (e.g. customers getting recommendations for shopping) or collaborate with it actively to make decisions (e.g. doctors using ML to detect tumor in X-ray scans). How much explainability matters is highly dependent on the context. For the recommendation example, we as consumers don’t really need an explanation why we were recommended an item. However, in scenarios where ML outcomes are used to make important decisions, explainability is important.
In order for users to effectively integrate ML outcomes into their important decisions, one can argue that trust has to be established first. (What we mean by trust in this topic is vague and deserves another blog post itself, but “The Mythos of Model Interpretability”2 by Z. Lipton is a good starting point.) But how is trust established? When the human actor 1) thinks the ML model makes reasonable and accurate predictions 2) can understand the reasons of the ML model’s outcomes, we can argue that the human actor starts to trust the model. Exact definitions of 1 and 2 change drastically depending on subject’s expertise level and stakes involved. The chart below shows how some AI applications are placed in these axes:
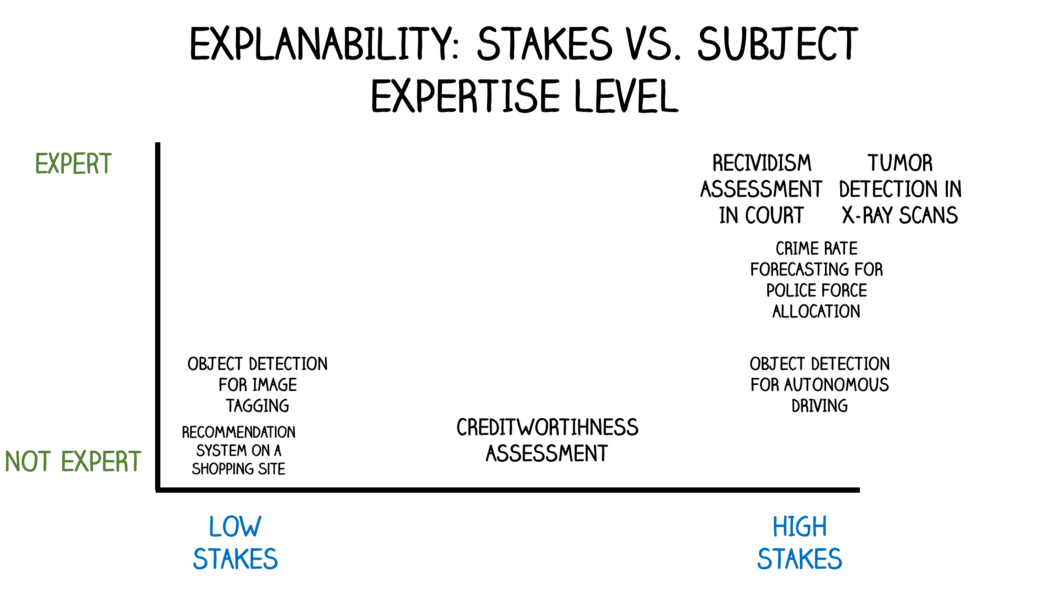
-
Recommendation system on a shopping site: Consumer is exposed to a recommendation system to get suggestions for new things to buy. Stakes are very low, the subject (consumer) does not necessarily need an explanation.
-
Creditworthiness Assessment: Consumer applies for a loan at a financial institution. Financial institution uses an ML model in the process (credit score), and the credit score is a factor to reject the loan application. In the US, the consumer is required to receive an Adverse Action notice3 on why they were rejected. The consumer does not need to know the details and inner workings of the credit model used, they just need a simple explanation in layman terms why they were not approved. Stakes in this scenario are significant, these decisions affect millions of lives financially.
-
Tumor Detection in X-Ray Scans: This is another exciting ML use case where a model is trained to detect cancerous tumors in X-ray scans, just recently performances on-par with human radiologists have been reported4. The subject of interest is expert radiologists, therefore a detailed explanation of the prediction needs to be presented. Furthermore, the stakes are very high as cancer is one of the deadliest diseases.
What future holds
There are societal implications, impacts, and ripple effects that many ML models used (knowingly or not knowingly) have in our lives. This is a growing field where standards are still being developed, and we have a long way to get there. It is very important that interpretability and societal aspects (fairness, bias, privacy) become a core part of the ML development cycle, not just an afterthought.
Here are some final thoughts about some issues and what future holds for explainability in ML:
-
There are regulations already in place (“Right to Explanation” in GDPR5), some specifically for certain industries (credit decisioning in the US, Fair Credit Reporting Act, FCRA6), and there is some activity from the White House to establish policies and regulations for other AI applications7. I think this is good progress, and I hope that regulations are put in place while not being too restrictive about new research making its way to use.
-
There has to be documentation standards each ML model/application is required to come with. The amount of detail can be specified with respect to stakes and subject’s level of expertise (see Stakes vs. Subject Expertise Level figure above). It should include (but not be limited to): how data is collected, what the target is, information about the data, how the model is trained, validated and tested, when the model works well and when it fails. Two promising examples in this regard are Datasheet proposal for Datasets8 and Google’s model cards9.
-
Until we get to maturity (in performance, standards, practices and regulations), it is very important that ML models are used in collaboration with humans unless the stakes are very low for the application of interest.
-
Once the maturity is reached, I think that it will be acceptable to use ML models on their own, and this will start to be rolled out with low stake applications. I am not good with predictions, but I think it’s plausible we use fully automated ML models for high stake applications in this century.
-
Getting there assumes the maturity being reached, which means that the trust is established. It is an open debate how much explainability one needs in order to establish trust, as long as the tool gets stuff done as intended. We are quite far away from there, but as the AI technology and standards become more mature, I think that explainability will become more important for pre-deployment phase. Once ML models “get stuff done” quite accurately, users will not necessarily need an explanation to understand them — they “just” work and they already passed the rigorous tests. A simple analogy for this is a thermostat: Many households have one, it consists of many modules, it goes through quality assurance (QA) before being sold and comes with datasheets. It is a low-stake situation (control the temperature in the house), but it gets stuff done — we trust it to control the temperature, and we don’t really need to understand how it works.
References
-
Lipton, Zachary C. “The mythos of model interpretability.” Queue 16.3 (2018): 31–57. ↩
-
https://www.state.nj.us/dobi/division_consumers/finance/creditreport3.htm ↩
-
https://blog.google/technology/health/improving-breast-cancer-screening/ ↩
-
Goodman, Bryce, and Seth Flaxman. “European Union regulations on algorithmic decision-making and a “right to explanation”.” AI Magazine 38.3 (2017): 50–57. ↩
-
https://www.consumer.ftc.gov/articles/pdf-0096-fair-credit-reporting-act.pdf ↩
-
https://www.whitehouse.gov/wp-content/uploads/2020/01/Draft-OMB-Memo-on-Regulation-of-AI-1-7-19.pdf ↩
-
Gebru, Timnit, et al. “Datasheets for datasets.” arXiv preprint arXiv:1803.09010 (2018) ↩