Thoughts on a Practical Generally Intelligent Agent
Yann Lecun published a paper called “A Path Towards Autonomous Machine Intelligence”1 in early 2022. It’s a great read and I highly recommend it. In this post, I will share some of my thoughts on this topic. Specifically, I am interested in how we can design a Generally Intelligent Agent using the concepts we have today. I will assume an agent with real world presence (i.e. a robot), but the ideas can be applied to virtual agents as well. It is heavily influenced by us humans, therefore there are some examples from humans.
Dr. Lecun has this image in his paper that illustrates the core components of his proposed system:
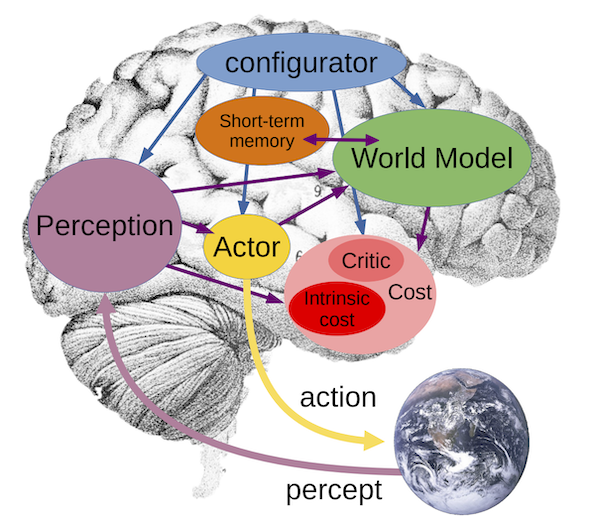
Similar to Dr. Lecun, I will view the problem using Reinforcement Learning (RL) concepts. We have an agent that receives a stream of measurements from outside and “inside”. The agent has a set of rewards (that may change over time) it wants to maximize over long term. The goal of this agent is to find a way (policy) to choose actions that will maximize its rewards, using the stream of data.
Measurements are temporal sequences
The agent receives a continuous stream of raw data from all the sensors available to it. (External sensors such as vision, audio, smell, touch, internal sensors such as pain, hunger, etc.) This can be represented as a concetenated stream of data coming from each sensor, with time as a component.
Actions are temporal sequences
The agent uses this stream of measurements to decide on which actions to take at a time step. There are different types of actions the agent can take, each color coded differently in the image. The actions can take real or discrete values. In this formulation, inaction is also a type of action.
Rewards are temporal sequences
After the actions are taken, the agent “receives” a set of rewards. These rewards are functions of the actions taken and the measurements received. The rewards can take any real value. Some of the reward functions are intrinsic, i.e. they are fixed functions of measurements and action taken. Some of the reward functions are extrinsic, i.e. they are learned functions of measurements and action taken. It’s important to note that the reward functions are internal to the agent, they are not values received from outside (which is the typical RL formulation).
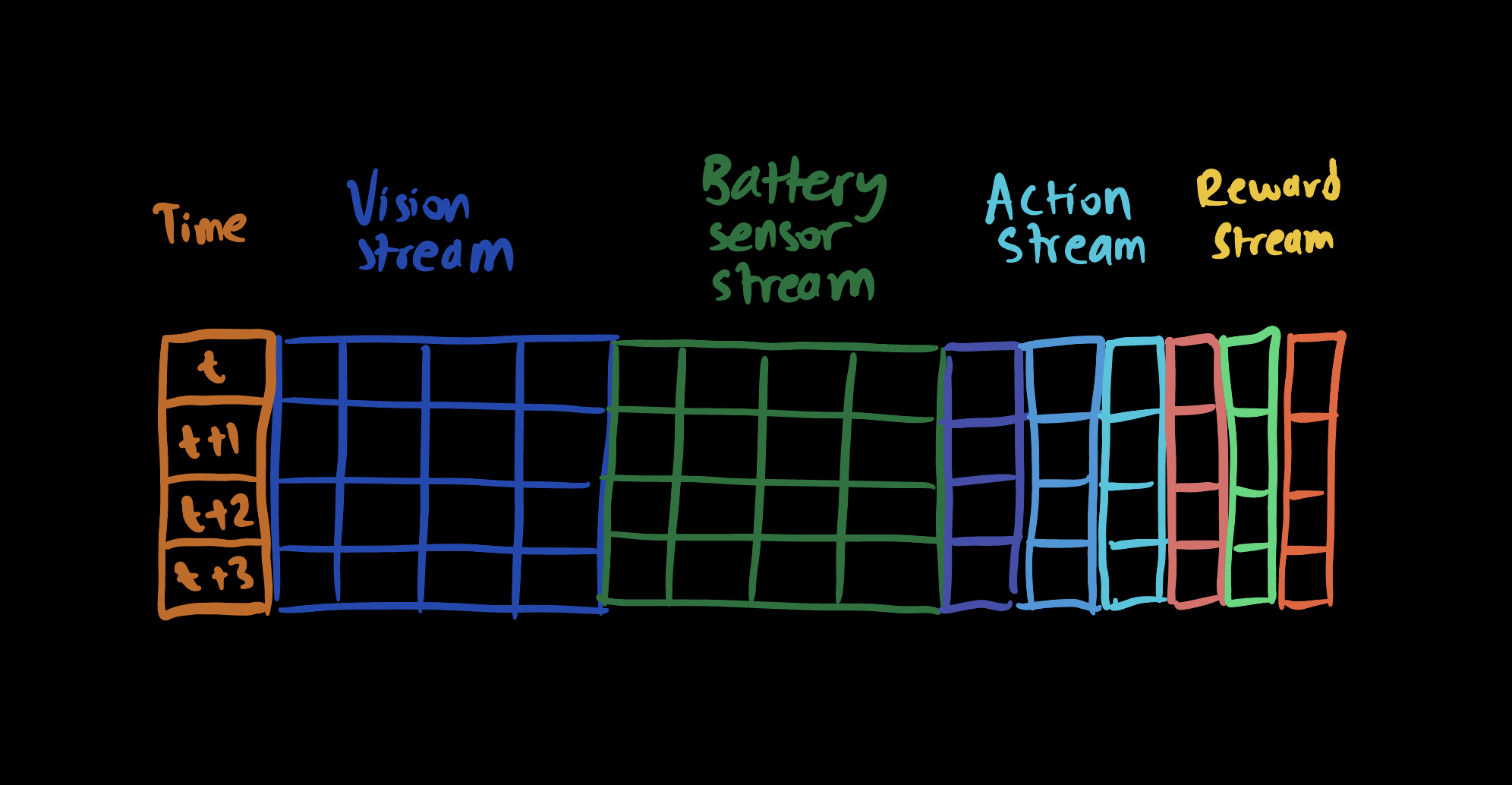
So far, we have the following system:
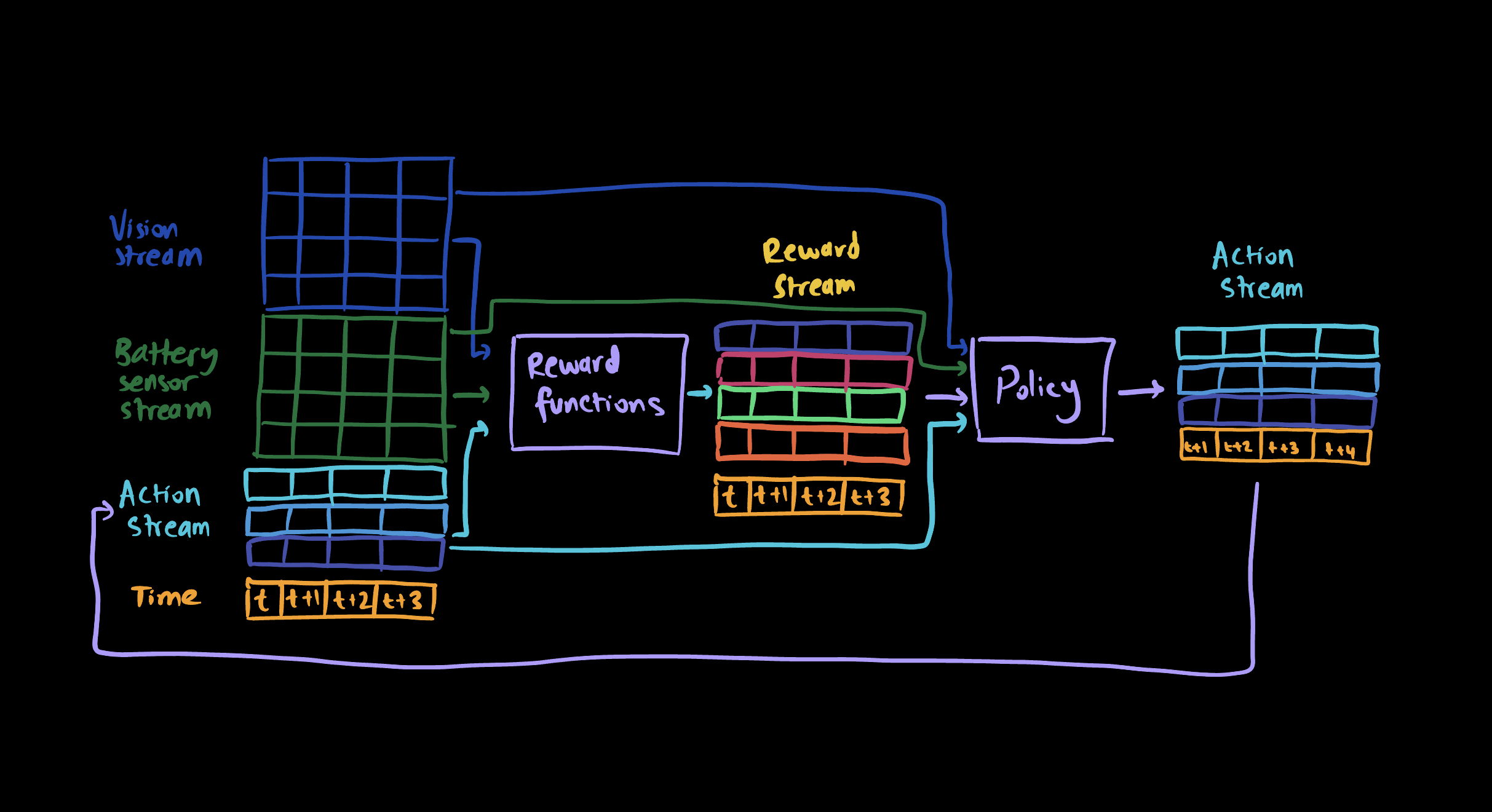
In this system,
- Everything is organized temporally. A column corresponds to a time step.
- The agent receives a stream of measurements internally and externally. It combines it with its action stream to compute its rewards.
- Measurements, actions and rewards are all used by the agent policy to decide on the next action.
There are three main components the agent uses (one not shown in the image):
- Data representation
- Policy
- Reward functions
Let’s go over the details of each of these components.
Tokenize everything
In the figure above, all the measurements, actions and rewards are represented as a stream of numbers. This is likely quite inefficient to store. Using the current state-of-the-art in sequence modeling, we can do better. We can tokenize everything.
Each type of measurement, action, reward and time (or delta time) have their own range of possible values they can take. We can split this range into a number of buckets and assign each bucket a unique id, i.e. token. The following figure illustrates this mechanism:
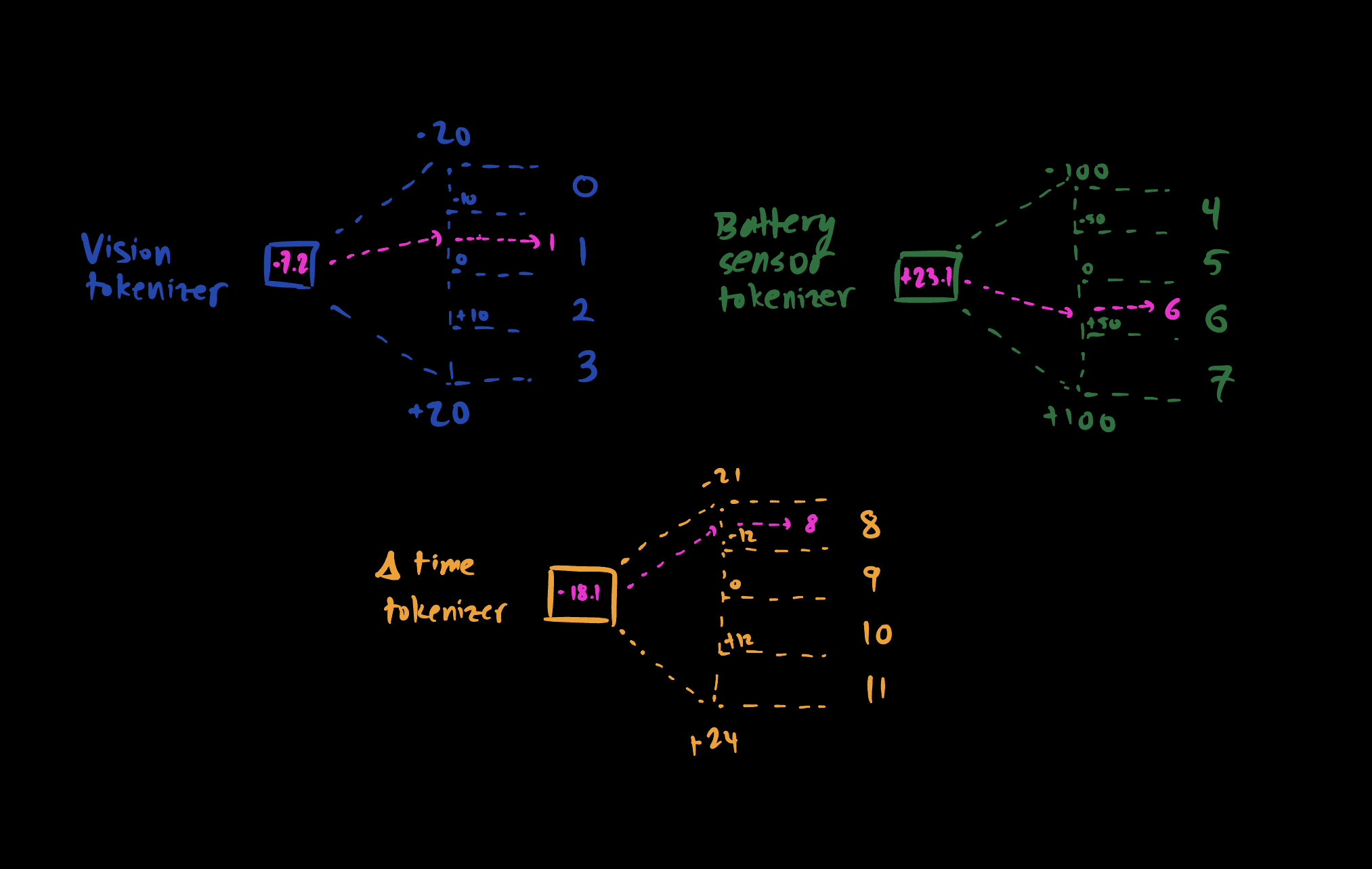
For example, the battery sensor measurement can take values between -100 and 100. This can be split into N buckets, and each bucket can be assigned a unique token. The same can be done for all the other data types. Same type of data is tokenized in the same way.
Now, we have a stream of data that is represented as a stream of tokens. These tokens will be mapped to a vector representation using an embedding layer. This embedding layer is used and learned by the agent policy and reward functions.
Agent policies
The agent policy is a function that takes a stream of past measurements, actions and rewards to produce a stream of actions. The agent uses the last K time steps as an input, which I will refer it as context.
For efficiency reasons, it makes sense to have two types of policies. One type of policy is low energy, i.e. it is fast and automatic (breathing, a world class cycler cycling etc.). The other type of policy is high energy, i.e. it is slow and requires more compute. Following Dr. Lecun’s paper and Dr. Kahneman’s book2, we have two types of policies:
- System 1 like policy: Fast, low computational cost
- System 2 like policy: Slow, high computational cost
Both policies take the same input, i.e. the context, and produce actions as outputs. Depending on the implementation, the agent can start its life with some System 1 policies, or it can all start as System 2 policies. Here is a diagram that illustrates the agent policy:
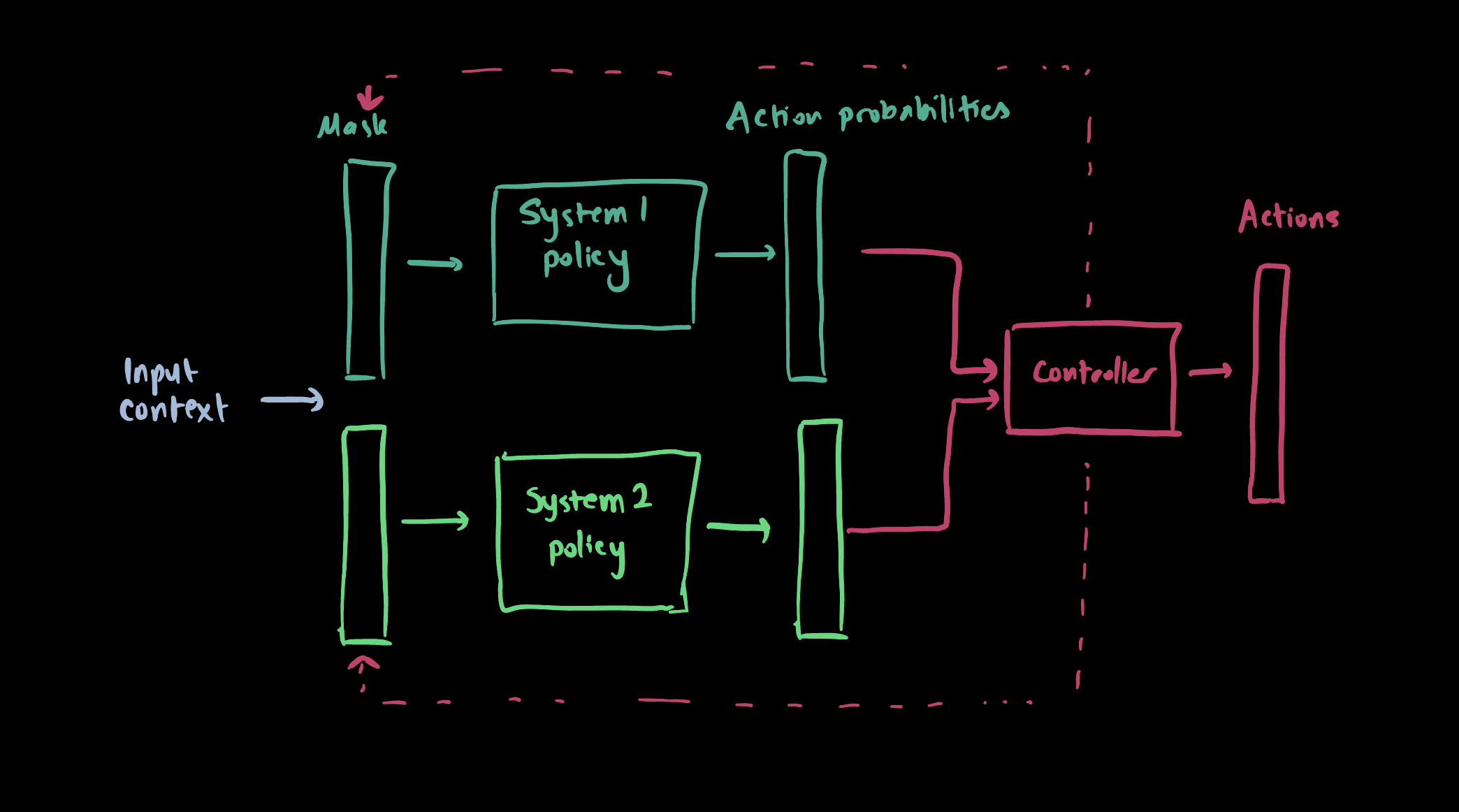
Here, both policies work in parallel, but with different focuses. Both take a mask vector as a configuration to decide which subset of input data to use and which subset of actions to produce. Action probabilities from both policies are merged by the controller. The controller has the capability of changing the mask (configuration) of the policies if it needs to.
Why do we need a controller? I think this is needed so that the agent can decide which policy to use at a given time step. For example, if the agent is in an unfamiliar or dangerous situation, it may want to use the System 2 policy to take over for actions. The unfamiliarity or danger should be detected by the controller through action probabilites. Let’s say there is a single action that’s controlled mostly by the System 1 (masks are configured to use only System 1). Let’s further assume that this action is a binary action, i.e. it can take two discrete values. In the “auto-pilot” mode, the System 1 policy should produce “sure” action probabilities, i.e. [1, 0] or [0, 1]. If the action probabilities are [0.55, 0.45], the controller should detect that the System 1 policy is not sure about the action, and it should switch to the System 2 policy by modifying the masks.
The fundamental challenge here is to understand why action probabilities are uncertain: Is it because the agent is in an unfamiliar situation, or is it because the relevant context is noisy? These sources of uncertainty are known as epistemic (knowledge) and aleatoric (noise) uncertainty. While we still don’t have a generic way to model these uncertainties, there has been good progress in this area with certain assumptions3.
How about the System 2 policy? System 2 policy by definition requires more compute. In this design, the System 2 policy leverages an internal model of understanding the measurements, i.e. how everything works. I call this the universe model (or world model, but we don’t need to be in the world for this 😊).
Universe model
The universe model is agent’s internal attempt of making sense of the data stream it receives and produces. It is a simulator that takes a stream of measurements, actions and rewards (i.e. context) as input, and produces a stream of measurements, actions and rewards as output. When we combine everything together, we have a data stream that looks like this:
The world model has access to a dataset of fixed size. Periodically, it trains itself using the data available in several ways:
- Learning within time: Mask a part of the context at time t. Using the unmasked input, learn to predict the masked input.
- Learning across time:
- Given context at time t, learn to predict the context at time t+1 (Vanilla auto-regressive model)
- Given context at time t, mask some parts of the input, learn to predict the context at time at t+1 (Masked auto-regressive model)
- Perform the same as above, but learn to predict the context at time t+K (K any negative or positive integer)
The simulator would accept the following arguments as input: Context, input mask, target mask, and delta t. This way of learning comes with nice features:
- Delta t = 0 setting could help agent learn concepts. In other words, it would “align” a concept across different medium of measurements it receives. I argue that seeing different media of the same concept repeatedly is the key to learn concepts, or higher-level abstractions.
- Delta t != 0 setting could help agent be able to plan/reason across different time settings.
- The agent can utilize the simulator to train its System 1 policies. For example, the System 1 policy can be trained with the simulator used as a critic.
Learning rewards
As I discussed above, the agent has two types of rewards: Intrinsic and extrinsic. Intrinsic rewards are computed by using fixed rules or functions (for example: “if battery reading is low, give negative reward”). Extrinsic rewards are the part that the agent learns over time. The extrinsic reward functions use intrinsic reward outputs as a part of their inputs - in early stages, the extrinsic reward shaping is heavily influenced by the intrinsic rewards. This is similar to how humans learn. We start with some intrinsic rewards (e.g. hunger). We associate our parents as our hunger inhibitors, and assign positive reward to their presence around us. In years, we associate money as a way to acquire food and inhibite hunger, and assign positive reward to money.
TL;DR
While there are many gaps and open questions, this write-up is my take on how an AGI agent could be structured. Here’s a summary of the key points:
- Everything is temporal sequences
- Everything is tokenized
- Agent wants to maximize its long term rewards (intrinsic and extrinsic). In order to maximize them, it updates some of its components:
- Policies and policy controller
- Measurement simulator
- Reward functions
Thanks for reading!